2025年4月30日
025-1.SPIKEプライム+ラズパイ+AIカメラ ロボットチャレンジ-第2回「AIカメラで物体を検出する」
この記事では「レゴ エデュケーションSPIKEプライム(以下、SPIKE)」とRaspberry Pi(以下、ラズパイ)とAIカメラを組み合わせたロボットを作る方法について紹介します。(文/松原拓也)
◆ データセットを作成する

前回に引き続き、公式のAIカメラ「Raspberry Pi AI Camera」を使って画像を認識します。
前回、物体検出のプログラム「imx500_object_detection_demo.py」を実行しましたが、実は正しく認識ができていない部分もありました。ラージハブは「laptop」、ミニフィグが「person」という見当違いな名前で表示されます。
本来なら「large_hub」や「minifig」と表示されるべきです。
この問題を解決するにはオリジナルのモデルを自作しないといけません。
モデルを自作するには、AITRIOSのWebサイトで公開されている「IMX500 Converter」というパッケージのツール(「imxconv-pt」や「imxconv-tf」)を使います。ただし、このツールは扱いが非常に難しいので、まずは「PyTorch」を使った画像認識から始めてみたいと思います。
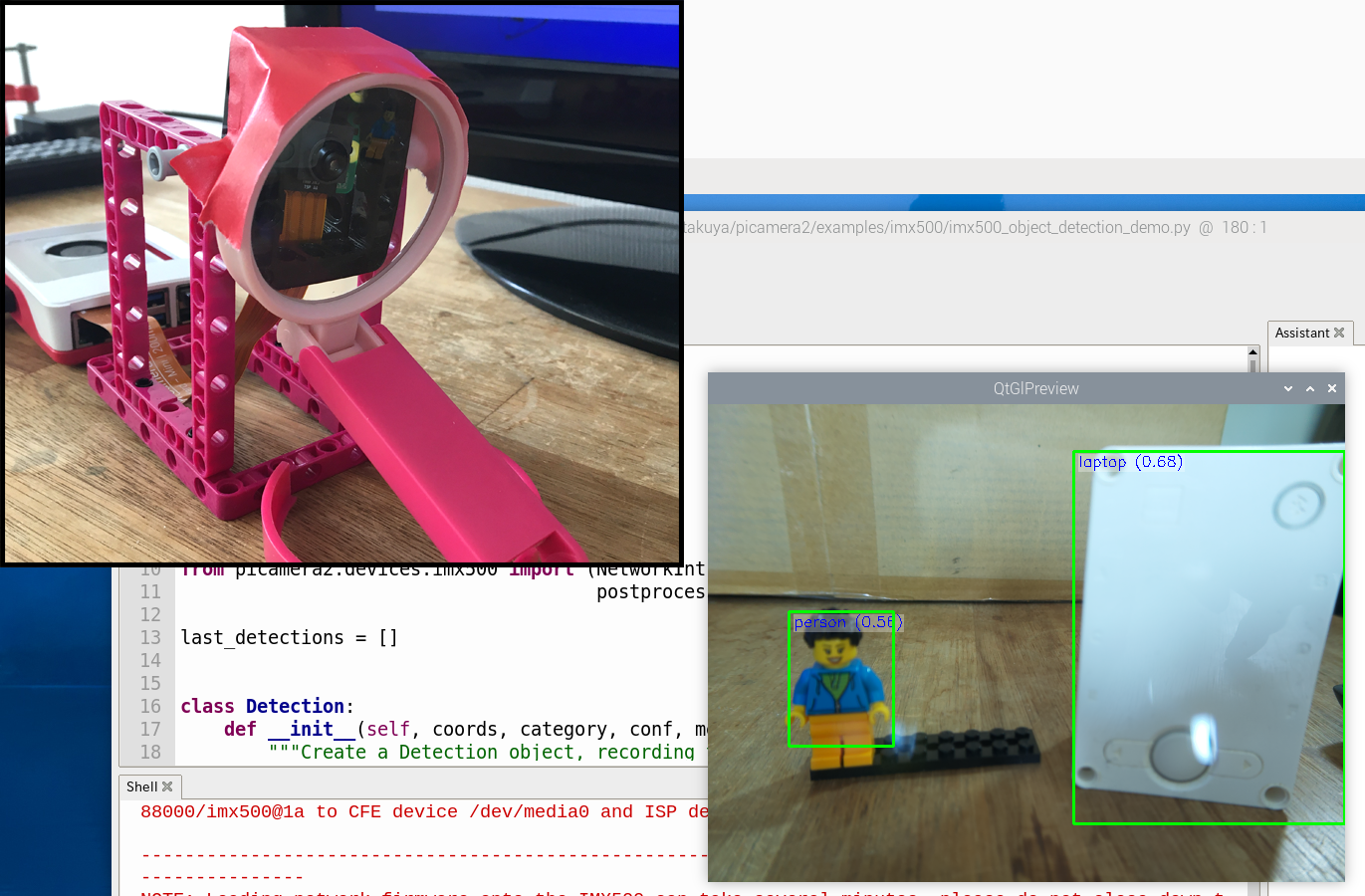
下準備として、カメラのピンボケを直します。
AIカメラにはプログラムでフォーカスを調整する機能があるのですが、難しそうなので物理的に調整することにします。粘着テープで100円ショップで買ったルーペを貼り付けました。完全ではありませんが、フォーカスが合うようになりました。
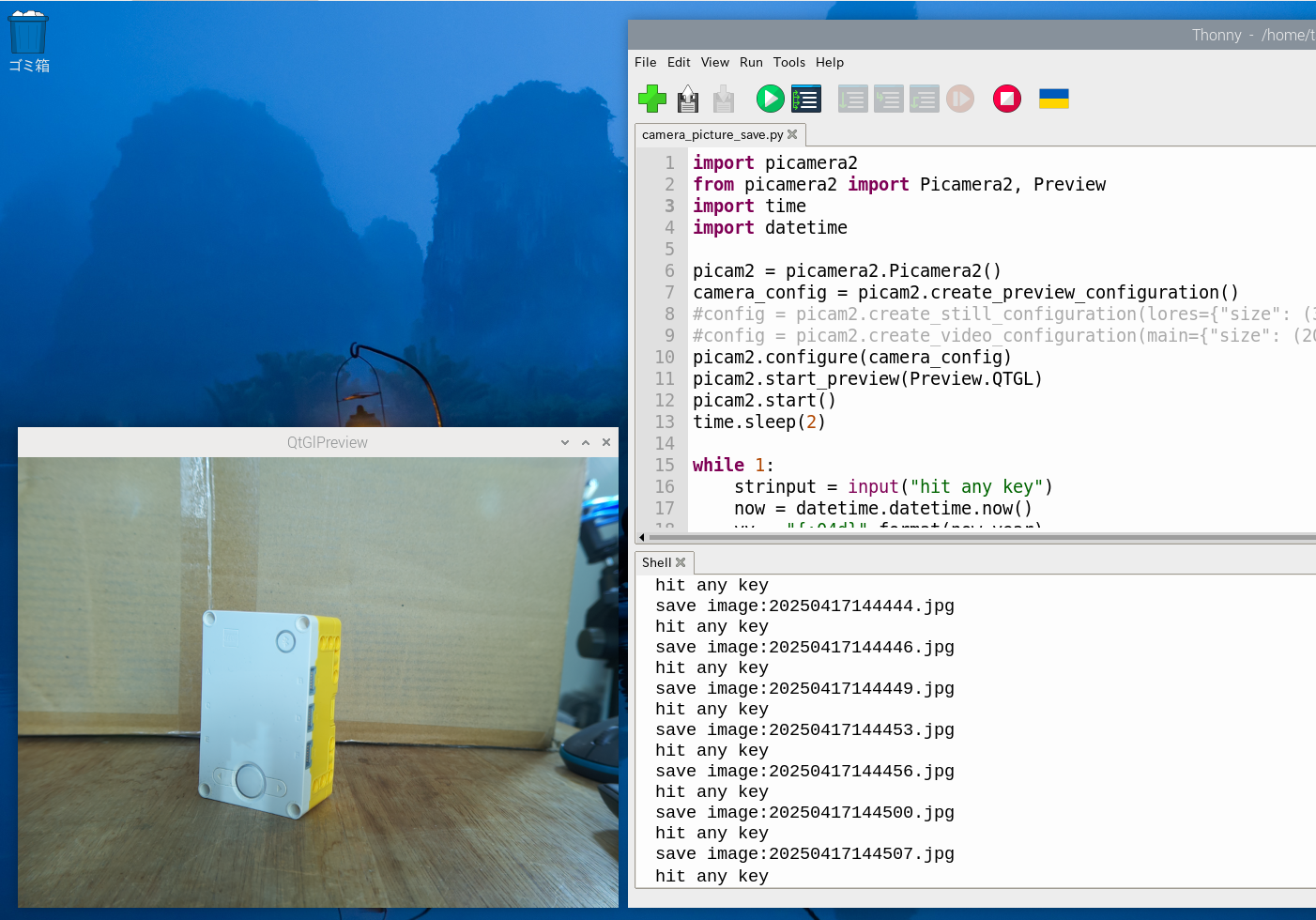
「データセット」を作成するため、連続でカメラを撮影できるプログラム(camera_picture_save.py)を作ってみました。データセットというのは学習するデータのことです。この場合は画像ファイルの集まりです。
プログラムの実行後、Enterキーを押すと、カメラの画像をJPEG形式で保存します。画像のサイズは640×480ピクセルです。ファイル名は撮影した日付と時間から自動的に設定します。手作業でファイル名を付けるより効率的です。
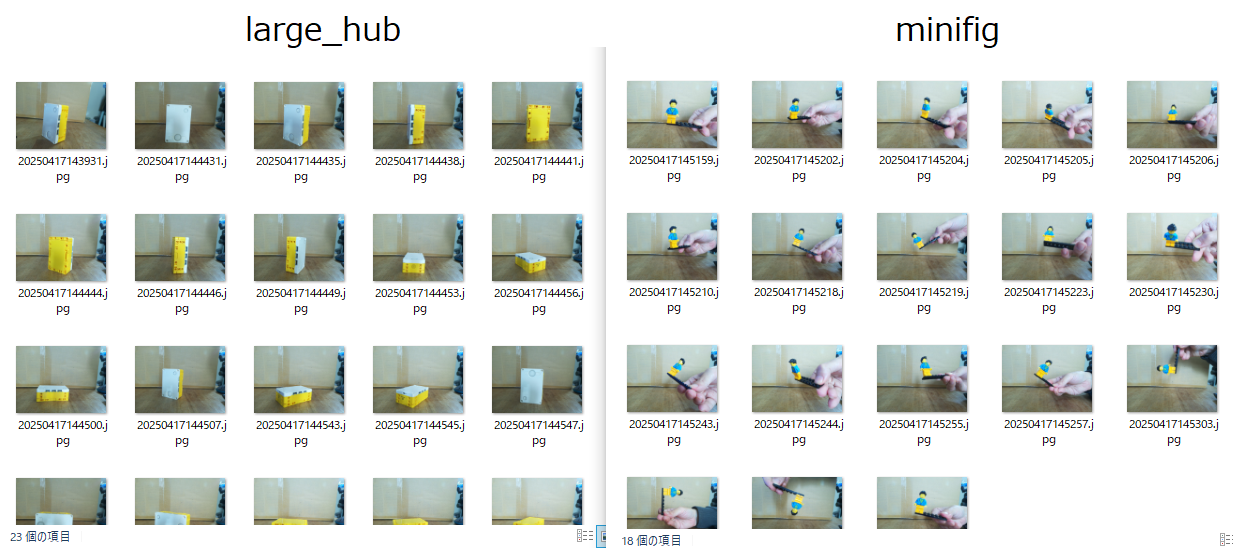
ラージハブとミニフィグを撮影してみました。画像は1件あたり15枚以上は必要だと思います。画像の認識率を上げるため、似たような画像だけではなく、向きを変えて撮影しましょう。
データセット作成中の様子です。
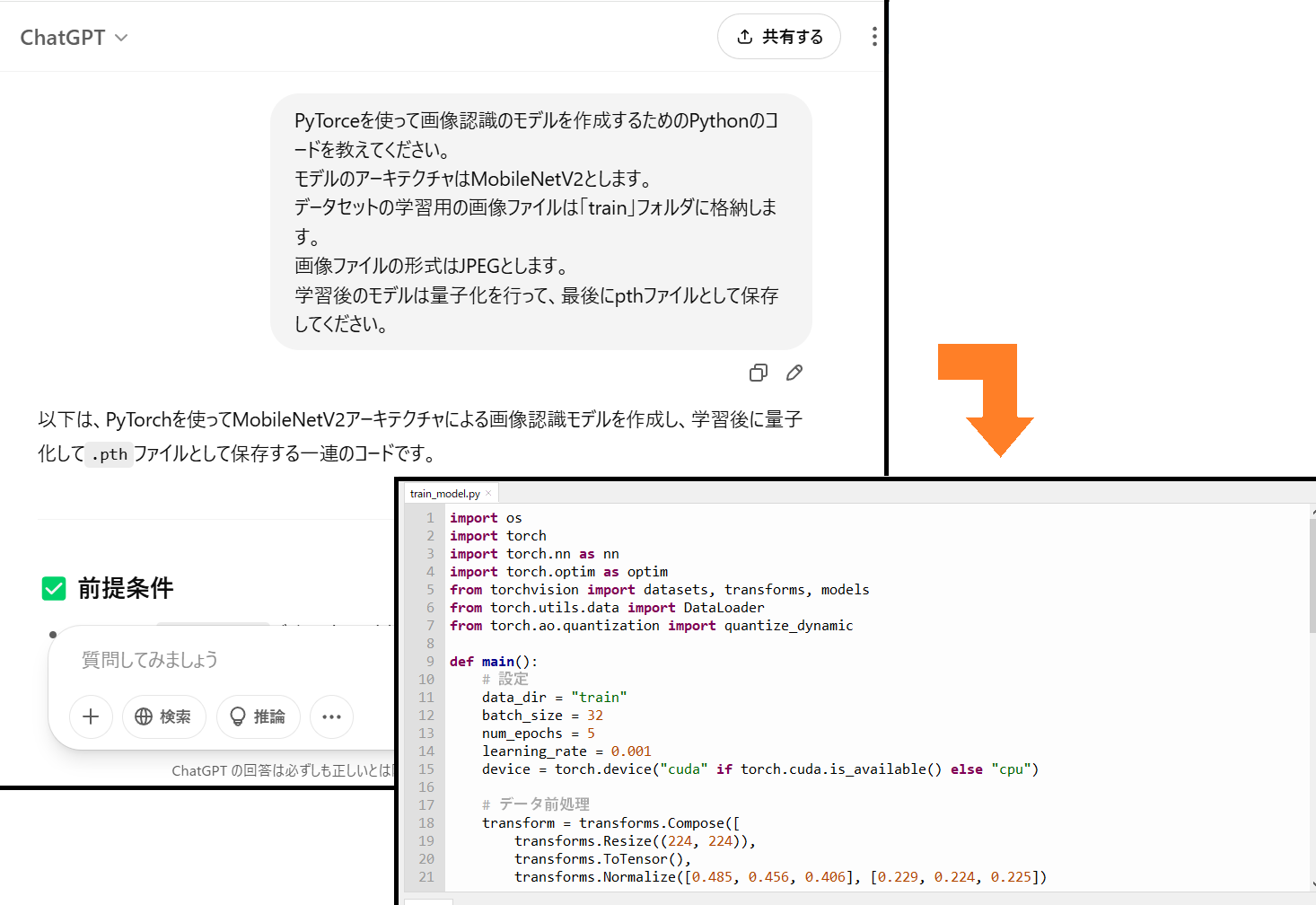
モデルを作ります。モデルをどうやって作ったらいいのか見当がつかないので、ChatGPTに質問してみました。邪道かもしれませんが、頼る手段がこれしか思い付きません。
https://chatgpt.com/
入力したプロンプトは次の通りです。
(ここから)
PyTorceを使って画像認識のモデルを作成するためのPythonのコードを教えてください。モデルのアーキテクチャはMobileNetV2とします。データセットの画像ファイルは「train」フォルダに格納します。画像ファイルの形式はJPEGとします。学習後のモデルは量子化を行って、最後にpthファイルとして保存してください。
(ここまで)
モデルには数多くの種類がありますが、「MobileNetV2」を選択しました。理由は物体認識のサンプルプログラムのモデルが「imx500_network_ssd_mobilenetv2_fpnlite_320x320_pp.rpk」だからです。「量子化」したのはファイルサイズを小さくするためです。PyTorch公式サイトによると「量子化とは、浮動小数点精度よりも低いビット幅でテンソルの計算と保存を行う手法を指します。」と解説しています。
プロンプトを入力すると、コードが表示されますので、それをテキストエディタにコピペして「train_model.py」というファイル名で保存します。
「PyTorch」を「PyTorce」とタイプミスしてしまったのですが、正しく認識されました。
生成されたコードをそのまま実行すると「models.mobilenet_v2」メソッドの行でワーニングが表示されてしまいます。「pretrainedという引数は将来削除される可能性があるので、weightsという引数を使用してください。」という警告が出ます。ChatGPTの学習データが古いのが原因だと思います。ここは手作業でコードを修正しました。
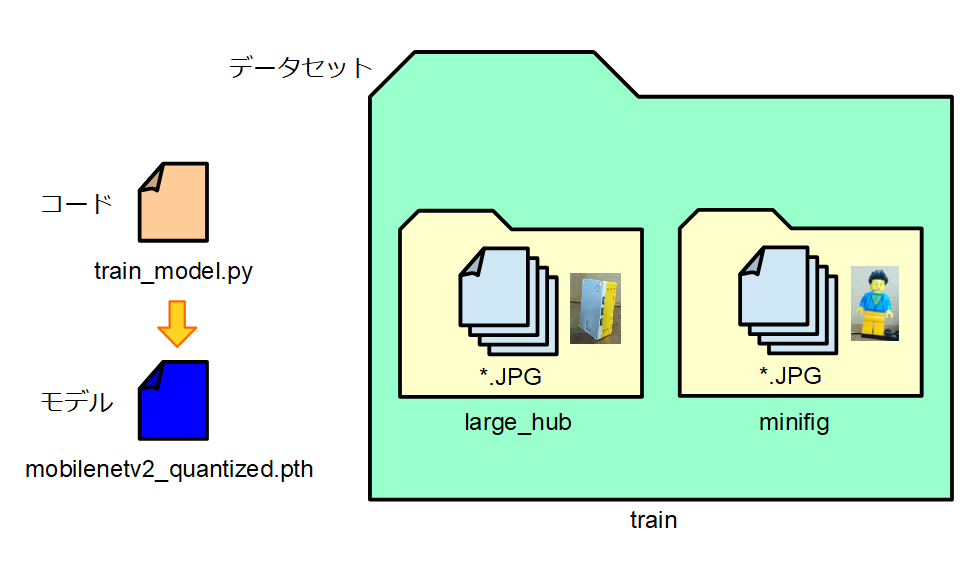
プログラム(train_model.py)と同じ階層に「train」という名前のフォルダを作ります。そのフォルダの中に「large_hub」と「minifig」というフォルダを作ります。各フォルダに先ほどの画像ファイルを格納します。
これでデータセットの準備は完了です。
◆ PyTorchをインストールする
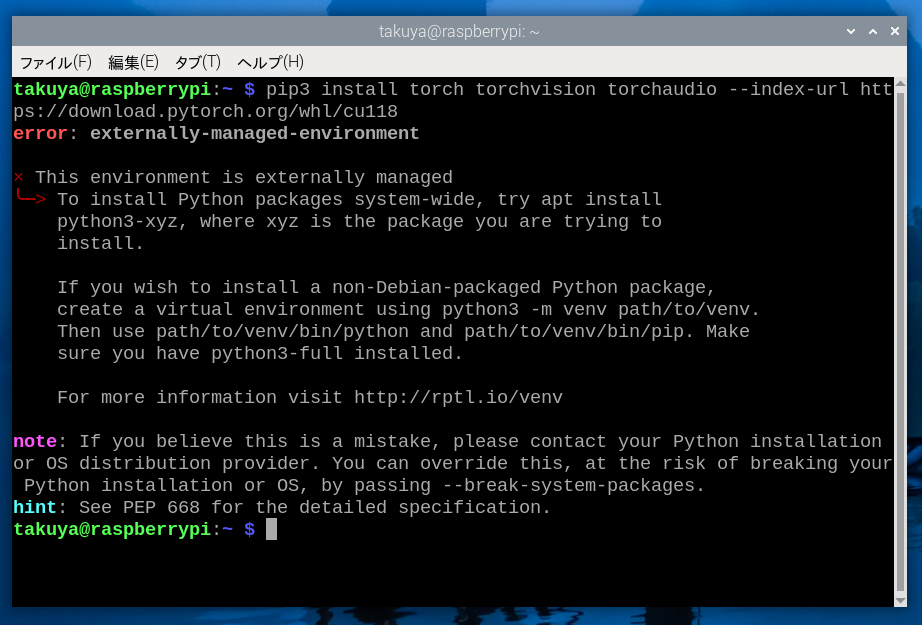
「PyTorch」というライブラリをインストールします。PyTorchはPython用の機械学習のフレームワークです。機械学習とはコンピュータにデータを与えて学習させることです(AIのことです)。今、機械学習は畳み込みニューラルネットワークという技術を採用しています。
PyTorchのパッケージは「torch」「torchvision」「torchaudio」の3つです。これを普通にインストールしようとすると「externally-managed-environment」というエラーが表示され、インストールが中断されます。環境を壊す危険がありますという警告です。
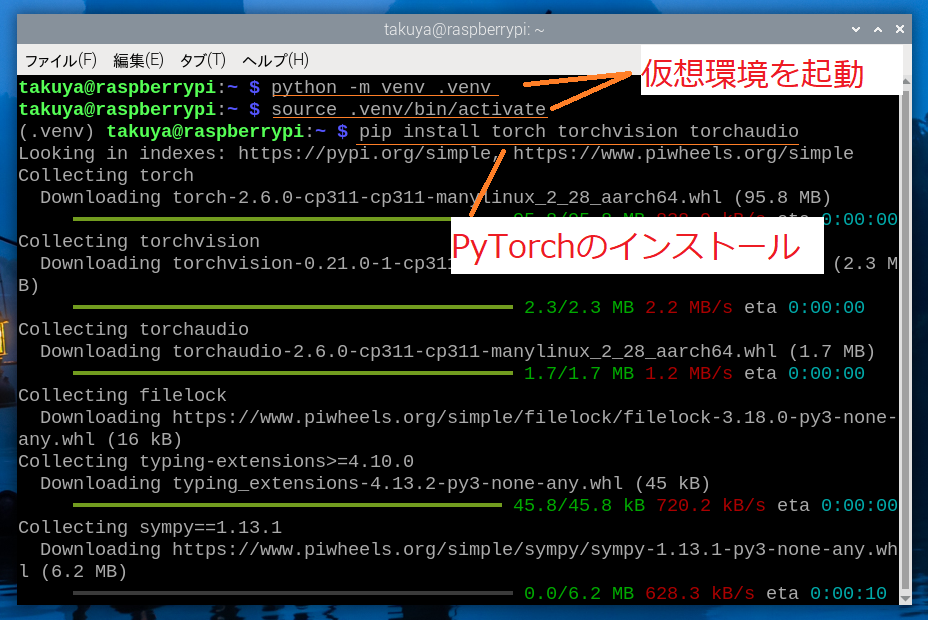
そこで、venvコマンドで仮想環境を起動します。仮想的な動作環境を作ることで、実際の環境を壊れないようにするという仕組みです。
ターミナル(LXTerminal)を起動して、「python -m venv .venv[Enter]」「source .venv/bin/activate[Enter]」と入力すると、「.veny」と名付けた仮想環境が起動します。プロンプトの先頭に「(.venv)」と表示されるようになります。
続いて「pip install torch torchvision torchaudio[Enter]」と入力すると、PyTorchがインストールされます。
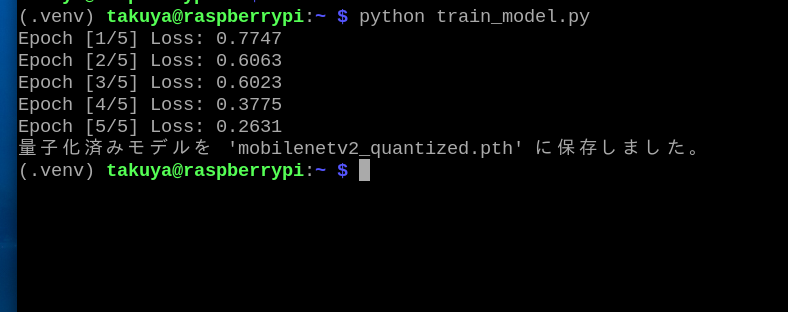
ターミナルで「python train_model.py[Enter]」と入力して、プログラムを実行します。この場合、Thonnyから実行することはできません(仮想環境にならず、エラーが出てしまいます)。
動作に成功すると、モデル(mobilenetv2_quantized.pth)が作成されます。
画面に表示される「Epoch」とは畳み込みニューラルネットワークの階層のことです。コードを修正すれば階層の数は変更することができます。
階層を増やしたほうが認識率が上がりそうな気がするのですが、そのまま使うことにします。
◆ 物体を認識する
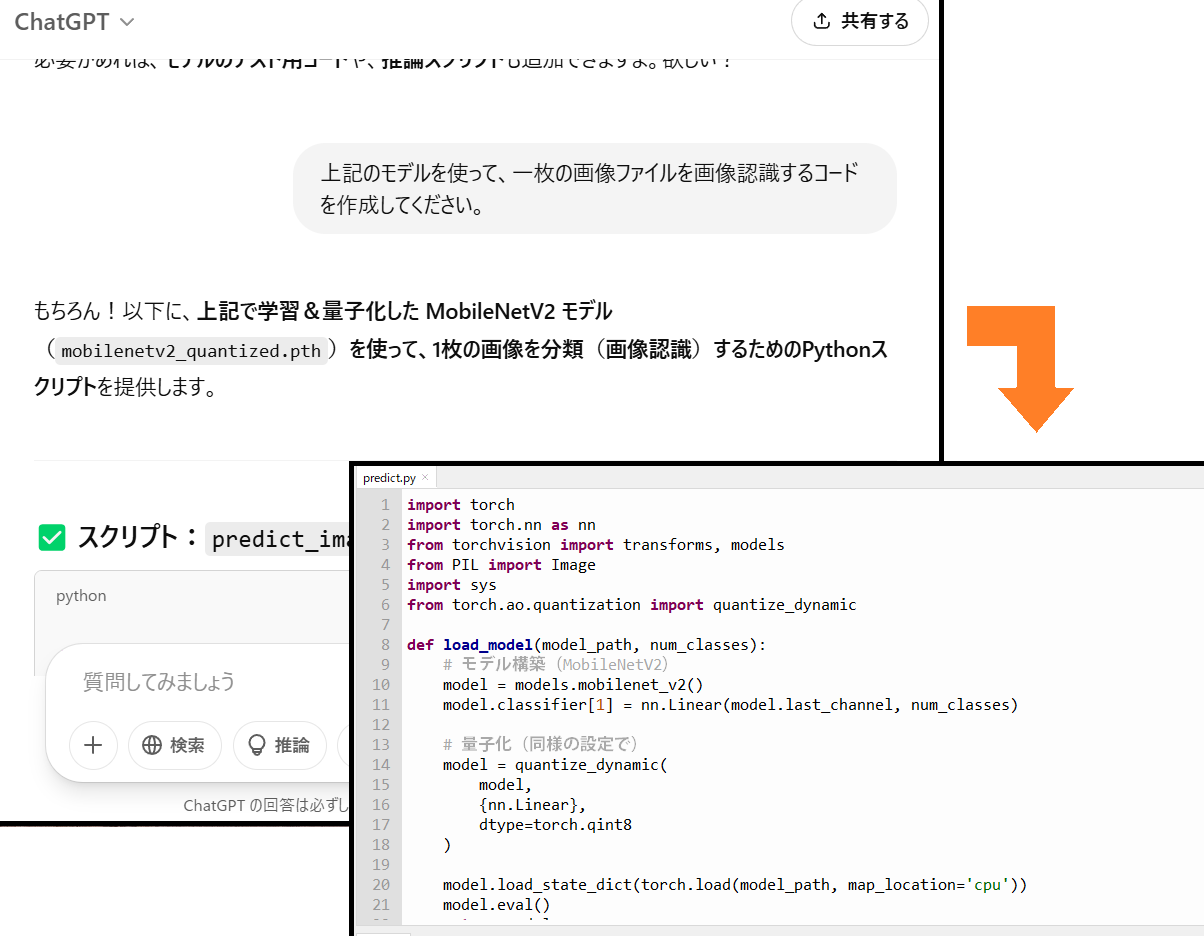
物体認識のプログラムを作成します。先ほどの
ChatGPTの回答に次の質問を追加します。
(ここから)
上記のモデルを使って、一枚の画像ファイルを画像認識するコードを作成してください。
(ここまで)
入力するとコードが表示されるので、それをテキストエディタにコピペして「predict.py」というファイル名で保存します。
これも先ほどと同じく「models.mobilenet_v2」メソッドで「pretrained」という引数が使われています。そのままだとワーニングが表示されてしまいますので、手作業で修正しました。
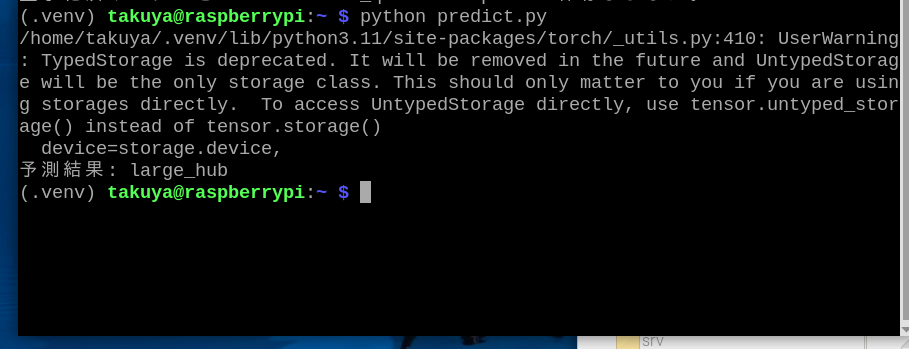
画像認識を行います。ターミナルで仮想環境を起動した状態で、「python predict.py[Enter]」と入力します。
変数「image_path」にラージハブの画像ファイル名(test_image.jpg)が格納された場合、「large_hub」と表示されます。正しく認識ができています。
「TypedStorage is deprecated」という謎のワーニングが表示されています。

変数「image_path」の中身を書き換えて実行を繰り返します。
画像にラージハブが写っていると「large_hub」、ミニフィグが写っていると「minifig」と表示されます。
画像認識が正常に機能しています。
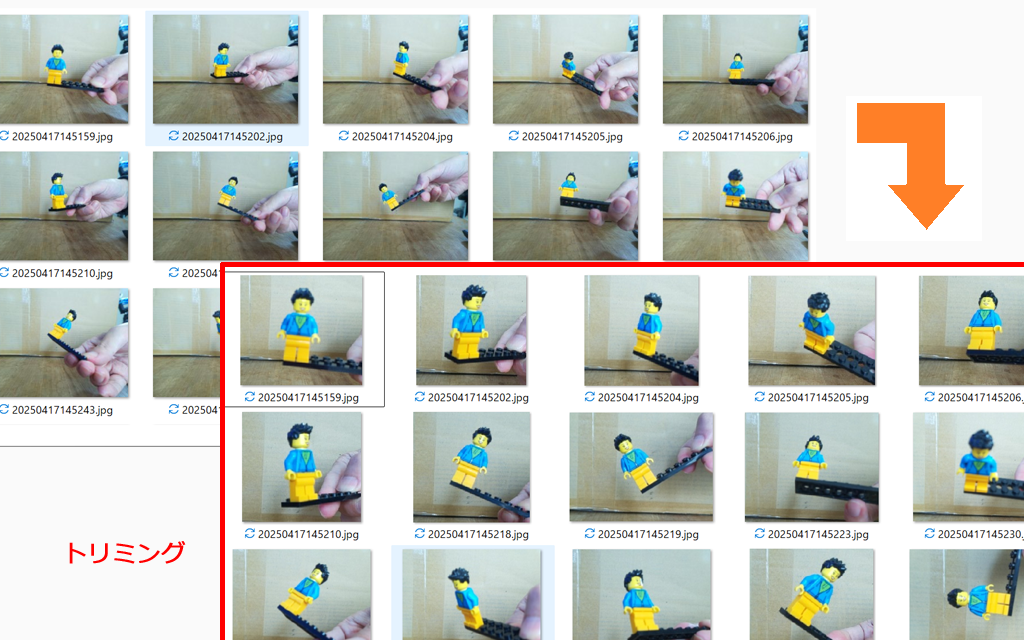
ちなみにミニフィグの画像に手が写ってしまっていて、認識率を下げているかもしれないと思い、1枚ずつ画像をトリミングしてみました。筆者の場合はIrfanViewというビューアを使いましたが、専用のツールを自作したほうが効率が良いと思います。
そして、再度モデルを作り直して、画像認識を実行してみましたが、なぜか性能的な違いはわかりませんでした。
◆ Windowsでも学習や画像認識ができます
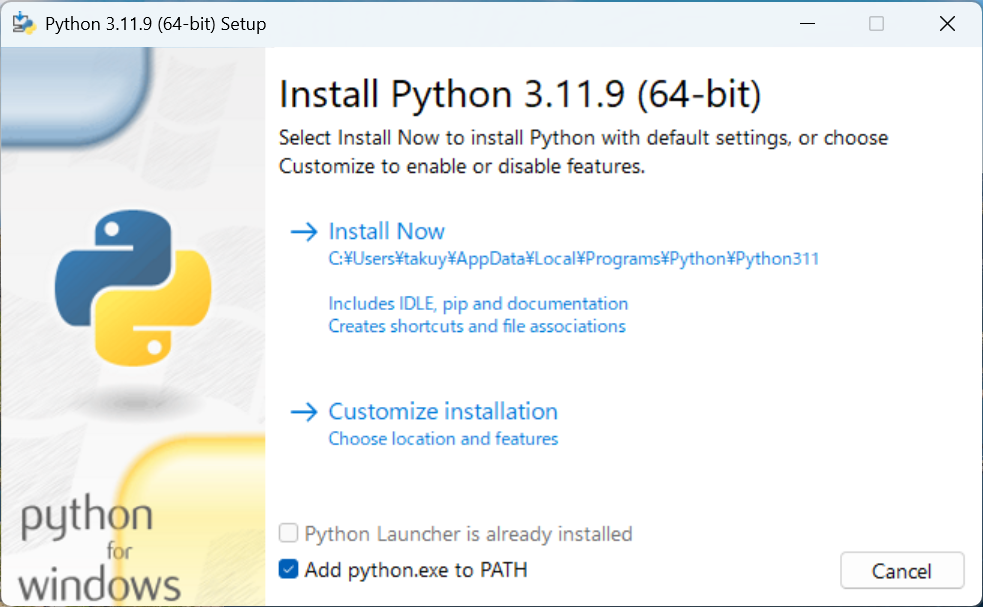
PyTorchはWindows版も存在します。なので、Windows搭載PCがあれば今回のモデル作成と画像認識のプログラムはそのまま動作します。実行方法は以下の通りです。
PCにWindows版のPythonをインストールします。PyTorchはPythonのバージョンが新しすぎると、正しく動作しないので古めのバージョンをインストールします。ここでは3.11.9をインストールしました。
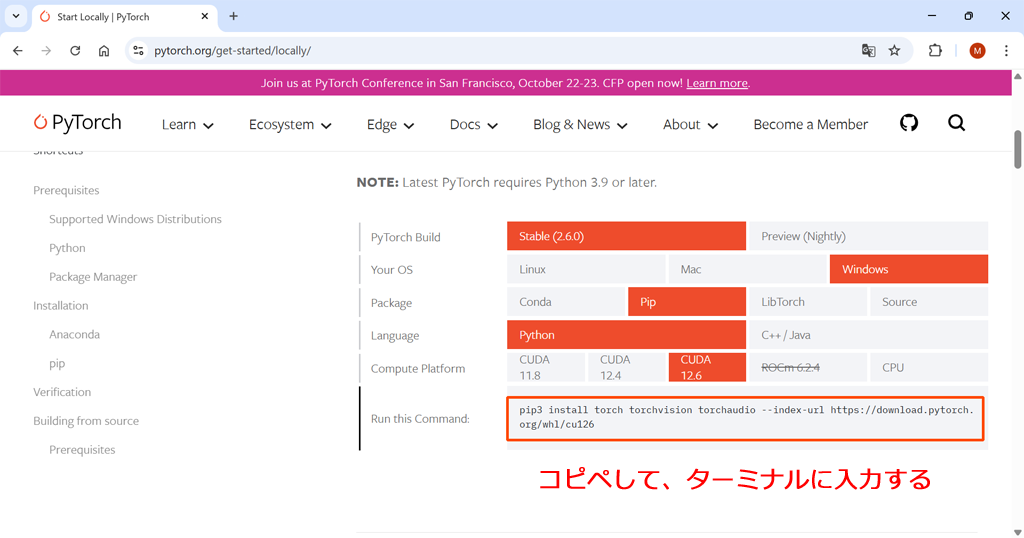
PyTorch公式サイトのトップページにインストールをするためのコマンドが書かれています。このコマンドをコピペして、ターミナル(Windowsの場合、コマンドプロンプトやPowerShell)で実行しましょう。
https://pytorch.org/
コマンドはPCの動作環境によって変化します。ここでは「Windows」「Pip」「Python」を選択します。「CUDA」というのはビデオカードのGPUを使って並列処理をする仕組みのことです。CUDA対応のビデオカードを持っていない場合には設定に意味はありません。
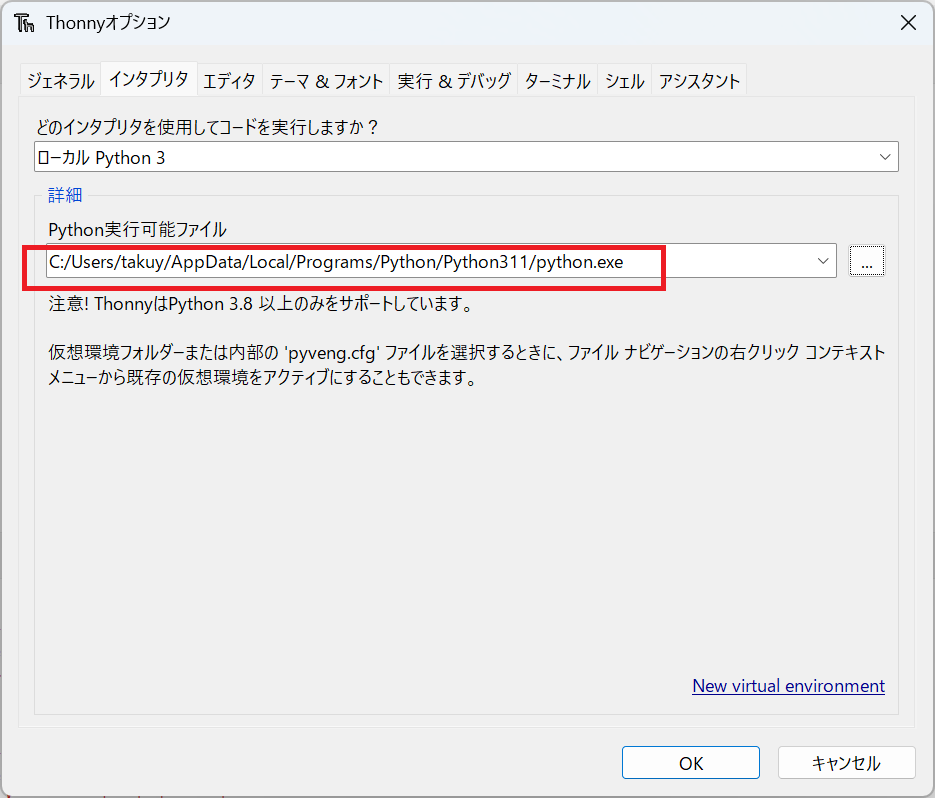
プログラムを「Thonny」で実行する場合、そのままだとThonnyフォルダ内にあるPythonを実行してしまいます。そこで、Thonnyのインタプリタ設定を選択して、実行するPyTorchのパスを変更します。
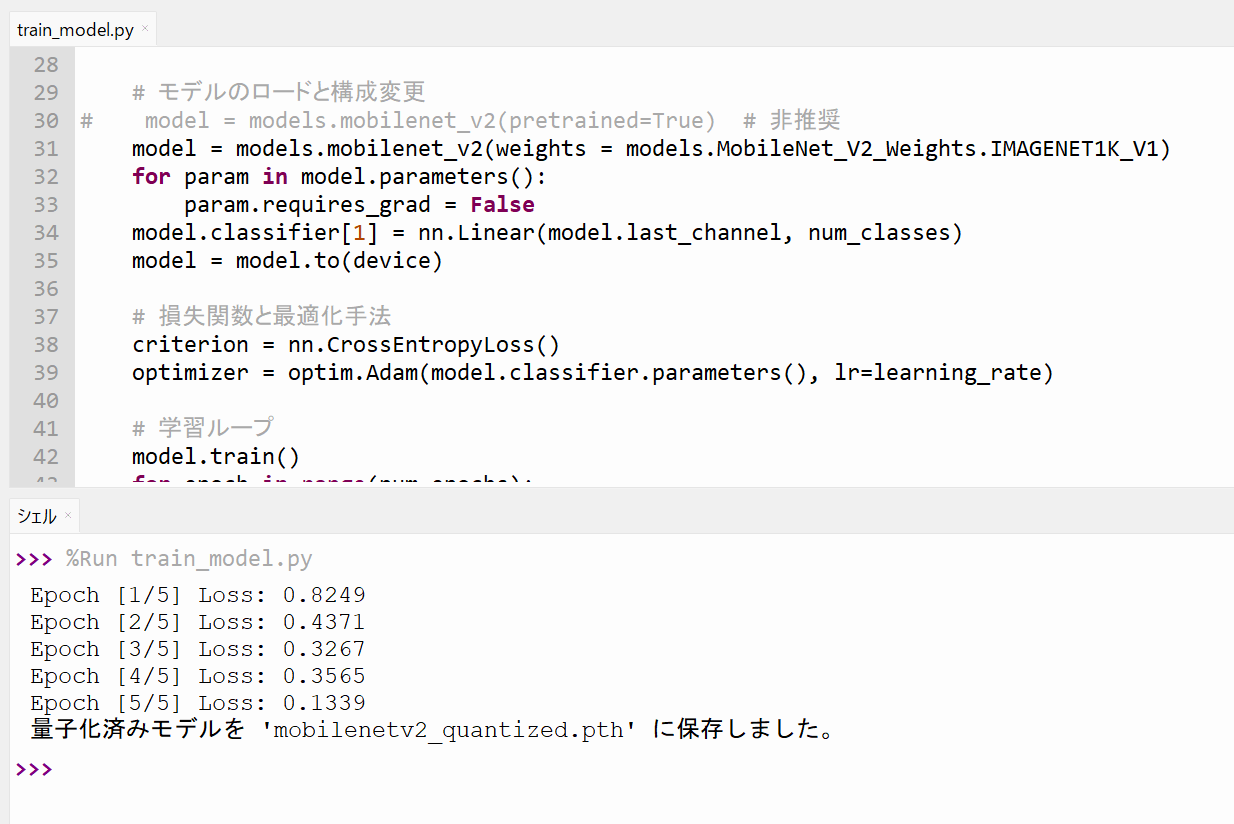
Thonnyでモデル作成のプログラム(train_model.py)を開いて実行します。あらかじめ「train」フォルダ(データセット)は「train_model.py」と同じ階層に配置しておきます。
実行に成功すると、モデルが作成されます。
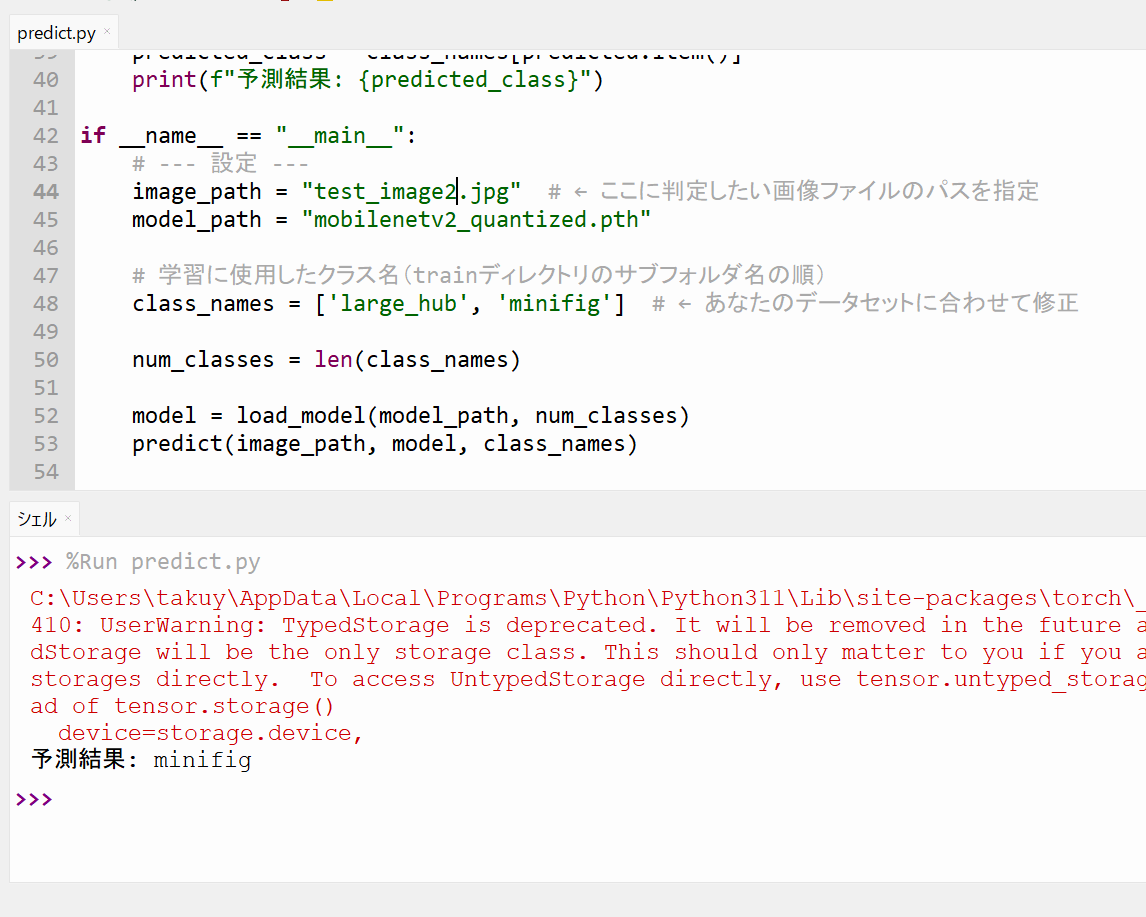
続いて、画像認識のプログラム(predict.py)を実行します。正しい認識結果が表示されました。
ここでも「TypedStorage is deprecated」というワーニングが表示されます。検索しても対策方法がよくわかりません。今度の宿題です。
無事に画像認識のモデルを作成することに成功しました。しかし、今回作成したモデルは、AIカメラの外側に存在するので、アクセラレータの機能を使っていません。本来ならIMX500 Converterでモデルを変換して、AIカメラに組み込む必要があります。次回はモデルの変換をやってみたいと思います。
当ブログの内容は、弊社製品の活用に関する参考情報として提供しております。
記載されている情報は、正確性や動作を保証するものではありません。皆さまの創意工夫やアイデアの一助となれば幸いです。